 Arbeitsschritte durchführen muss, entsteht dann,
wenn die Datemenge in genau umgekehrter Richtung bereits vorsortiert ist, da jedes mal das Markenelement an den Anfang der bereits sortierten Menge
geschaufelt werden muss.
Arbeitsschritte durchführen muss, entsteht dann,
wenn die Datemenge in genau umgekehrter Richtung bereits vorsortiert ist, da jedes mal das Markenelement an den Anfang der bereits sortierten Menge
geschaufelt werden muss.
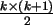 , wobei k die aktuelle
Markenposition darstellen soll (Gaussche Formel zur Berechnung der natürlichen Zahlen zwischen 1 und k). Eingesetzt und aufgelöst ergibt
sich
Arbeitsschritte im worst case, wobei n die Anzahl der Elemente in der zu sortierenden Menge bezeichnet.
Die Abschätzung nach oben (worst case) der Laufzeitkomplexität für den InsertionSort ist somit:
, wobei k die aktuelle
Markenposition darstellen soll (Gaussche Formel zur Berechnung der natürlichen Zahlen zwischen 1 und k). Eingesetzt und aufgelöst ergibt
sich
Arbeitsschritte im worst case, wobei n die Anzahl der Elemente in der zu sortierenden Menge bezeichnet.
Die Abschätzung nach oben (worst case) der Laufzeitkomplexität für den InsertionSort ist somit: 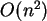
Der schlechteste Fall (worst case), also bei dem der InsertionSort wirklich
Arbeitsschritte durchführen muss, entsteht dann,
wenn die Datemenge in genau umgekehrter Richtung bereits vorsortiert ist, da jedes mal das Markenelement an den Anfang der bereits sortierten Menge
geschaufelt werden muss.
Die folgende Tabelle zeigt die Anzahl der Vergleichs- und Tauschoperationen auf einer Datenemnge, welche mit Zufallszahlen gefüllt wurden, und bei jedem Test um zusätzliche Elemente erweitert wurde.
| Elemente | Vergleiche | Tauschoperationen |
| 5 | 7 | 6 |
| 10 | 24 | 18 |
| 100 | 2680 | 2592 |
| 1000 | 243948 | 242964 |
| 10000 | 25194592 | 25184610 |
Die gleichen Test wurden mit einer Datenemenge durchgeführt, die in umgekehreter Richtung vorsortiert war um den worst case für den InsertionSort zu simulieren. Sieht man sich die Vergleichszahlen an, findet sich dort die Formel der Arbeitsschritte wieder.
| Elemente | Vergleiche | Tauschoperationen |
| 5 | 10 | 10 |
| 10 | 45 | 45 |
| 100 | 4950 | 4950 |
| 1000 | 499500 | 499500 |
| 10000 | 49995000 | 49995000 |
Man beachte, dass die Anzahl der Tauschoperationen und der Vergleiche identisch sind. Dies rührt von der Tatsache, dass der InsertionSort das Markenelement bis nach ganz vorne in die Datenmenge einreiht und genauso viele Vergleiche durchführt.
Nächste Seite: Implementierung
Aufwärts: InsertionSort
Vorherige Seite: Beispiel
Inhalt