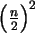 .
.
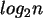 kleinere
Teilprobleme, wobei ``n'' die Anzahl der Elemente in der Gesamtmenge ist. Daraus resultiert eine Laufzeitkomplexität
von
kleinere
Teilprobleme, wobei ``n'' die Anzahl der Elemente in der Gesamtmenge ist. Daraus resultiert eine Laufzeitkomplexität
von
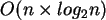 .
.
Der MergeSort besitzt weiterhin die Eigenschaft ``stabil'' zu sein, was nicht alle Sortieralgorithmen für sich beanschpruchen können. Diese Eigenschaft bezeichnet das Verhalten des Algorithmus, wie er mit gleichen Elementen in einer Menge, welche schon nebeneinander liegen, umgeht. Stabile Algorithmen stellen sicher, daß sich die relative Ordnung dieser Elemente zueinander nicht ändert. Somit wird sich beim Ablauf eines stabilen Algorithmus auf einer bereits sortierten Datenmenge, welche gleiche Elemente mehrfach beinhaltet, nichts ändern. Dieser Effekt ist im Allgemeinen erwünscht, jedoch, wie bereits erwähnt, beweisen nicht alle Algorithmen diese Eigenschaft.
Die nachfolgenden Tabellen sollen jeweils die Anzahl der Vergleichs- (erste Spalte) und Tauschoperationen (zweite Spalte) für die jeweilige Implementierung in unterschiedlichen Scenarios darstellen; aus ihnen wird aus ersichtlich, wie wenig sich die Implementierungen, die in-place Variante ausgenommen, in ihrem Laufzeitverhalten unterscheiden.
| Elemente | Standard | Iterativ | Sedgewick | In-Place | ||||
| 5 | 7 | 12 | 8 | 20 | 12 | 12 | 7 | 11 |
| 10 | 20 | 34 | 25 | 50 | 34 | 34 | 20 | 26 |
| 100 | 548 | 672 | 565 | 800 | 672 | 672 | 548 | 2610 |
| 1000 | 8723 | 9976 | 8729 | 11000 | 9976 | 9976 | 8723 | 252484 |
| 10000 | 120140 | 133616 | 123377 | 150000 | 133616 | 133616 | 120140 | 25390964 |
Wie zu sehen ist, ist die Anzahl der Tauschoperationen für die in-place Variante deutlich größer als bei den anderen Implementierung. Wie schon erwähnt, steigt
diese quadratisch an. Eine erste Näherung wäre
.
| Elemente | Standard | Iterativ | Sedgewick | In-Place | ||||
| 5 | 7 | 12 | 8 | 20 | 12 | 12 | 7 | 0 |
| 10 | 19 | 34 | 21 | 50 | 34 | 34 | 19 | 0 |
| 100 | 356 | 672 | 372 | 800 | 672 | 672 | 356 | 0 |
| 1000 | 5044 | 9976 | 5052 | 11000 | 9976 | 9976 | 5044 | 0 |
| 10000 | 69008 | 133616 | 71712 | 150000 | 133616 | 133616 | 69008 | 0 |
Wie ersichtichtlich, ändern sich die Werte für die Implementierungen nur sehr geringfügig. Eine Ausnahme ist hier die in-place Variante. Wie später noch zu sehen wird, spiegelt sich hier eine Eigenschaft des MergeSorts wieder. Er ist im Allgemeinen unabhängig von der Vorsortierung der Datenmenge gleich effizient.
| Elemente | Standard | Iterativ | Sedgewick | In-Place | ||||
| 5 | 5 | 12 | 5 | 20 | 12 | 12 | 5 | 15 |
| 10 | 15 | 34 | 15 | 50 | 34 | 34 | 15 | 60 |
| 100 | 316 | 672 | 316 | 800 | 672 | 672 | 316 | 5266 |
| 1000 | 4932 | 9976 | 4932 | 11000 | 9976 | 9976 | 4932 | 504432 |
| 10000 | 64608 | 133616 | 64608 | 150000 | 133616 | 133616 | 64608 | 50059608 |
Wie man sehen kann, erzielt die in-place Variante ungeheuer große Zahlen für die Tauschoperationen, was sie letztlich sehr ineffizient macht.
Die erste Näherung kann man nun verfeinern. Für den worst case der in-place Variante läßt sich eine genaure Zahl der Tauschoperationen mit der folgenden Formel berechenen,
wobei sie nur exakte Zahlen liefert, wenn n eine Zweierpotenz ist.
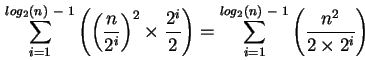
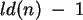 , wobei der Wert des
, wobei der Wert des 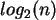 abgerundet wird. Dies ist in Programmiersprachen sehr einfach durch eine Integerdivision oder einen expliziten bzw. impliziten ``cast'' realisierbar.
abgerundet wird. Dies ist in Programmiersprachen sehr einfach durch eine Integerdivision oder einen expliziten bzw. impliziten ``cast'' realisierbar.
Nächste Seite: ShellSort
Aufwärts: MergeSort
Vorherige Seite: ``in-place''
Inhalt