Eines der ersten Probleme, auf das man trifft, ist:
Welche arithmetische Funktion soll verwendet werden, um die Tabellenadressen zu berechnen,
um erstens Kollisionen
möglichst zu vermeiden und eine gute Gleichverteilung der berechneten Hash-Werte zu erreichen. Dafür gibt es
verschiedene Verfahren:
Divisionsmethode:
Es hat sich als vorteilhaft erwiesen, für die Anzahl der Datensätze M eine Primzahl zu verwenden,
wobei M die Menge der Datensätze ist, die im verfügbaren Speicher untergebracht werden können.
Der Wert der Hashfunktion, also der Tabellenplatz kann durch die einfache Formel  berechnet
werden, wobei k einen beliebigen Schlüssel bezeichnet, der auf eine Adresse in unserer Tabelle
abgebildet werden soll.
Nehmen wir an, wir haben den Schlüssel
berechnet
werden, wobei k einen beliebigen Schlüssel bezeichnet, der auf eine Adresse in unserer Tabelle
abgebildet werden soll.
Nehmen wir an, wir haben den Schlüssel "KEY" und wollen für diesen mittels der obigen Hashfunktion
den Hashwert berechnen. Die angenommene Größe unserer Tabelle soll  betragen. Eine Möglichkeit
besteht darin, den Schlüssel mit Hilfe des Binärcodes zu codieren. Die Stelle des zu codierenden
Buchstabens im Alphabet entspricht dabei jeweils einem fünfstelligen Binärcode.
betragen. Eine Möglichkeit
besteht darin, den Schlüssel mit Hilfe des Binärcodes zu codieren. Die Stelle des zu codierenden
Buchstabens im Alphabet entspricht dabei jeweils einem fünfstelligen Binärcode.

Setzt man den Binärcode des Schlüssels zusammen, erhält man 0100110010111001, was in eine
Dezimalzahl umgerechnet 11449 ergibt. Setzt man diese Zahl nun in die Formel ein, so
erhält man
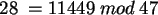 . Der Schlüssel hat die Hash-Adresse 28, d.h.
. Der Schlüssel hat die Hash-Adresse 28, d.h. "KEY" wird
auf die Position 28 in unserer Tabelle abgebildet.
Denkt man einen Schritt weiter, läßt sich leicht erkennen, welches Problem diese Methode aufwirft.
Erstens kann es vorkommen, daß zwei verschiedene Schlüssel denselben Hash-Wert erhalten und somit auf
die selbe Stelle in der Tabelle abgebildet würden, das zweite Problem ergibt sich, wenn man versucht,
Hash-Werte für sehr große Schlüssel, z.b. "EXTRALONGKEY" zu berechnen.
Würde man den Binärcode für diesen Schlüssel berechnen, wäre das Ergebnis eine Kette von 60 Bits
Länge, welche sowohl zur dezimalen Darstellung, als auch für die Verwendung in arithmetischen
Funktionen nicht mehr geeignet ist.
Wie kann man dieses Problem nun umgehen?
Indem wir den Schlüssel schrittweise transformieren. Hierzu wird das Horner-Schema verwendet.
Der oben genannte Schlüssel "KEY", bzw. die Zahl 11449 läßt sich zur Basis 32 folgendermaßen
darstellen:

Das elegante an dieser Darstellung ist, daß 11, bzw. 5 und 25 genau den Stellen von K, E und Y
im Alphabet entsprechen.
Dargestellt im Horner-Schema entspricht dies
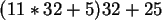 , womit die Hash-Funktion ohne Umweg über
die Binärcodierung direkt berechnet werden kann.
, womit die Hash-Funktion ohne Umweg über
die Binärcodierung direkt berechnet werden kann.
Code:

Dieser Code (Sedgewick) berechnet den Hashwert
direkt, wobei die Berechnung modulo M verhindert, das ein Überlauf entsteht, da das Ergebnis der Zeile 8
welche das Ergebnis der Berechnung
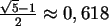 ist.
Um die Nachkommastellen zu erhalten genügt es, modulo 1 zu rechnen. Der so erhaltene Wert wird mit der Anzahl
M der Tabellenplätze multipliziert und man erhält den Hash-Wert
ist.
Um die Nachkommastellen zu erhalten genügt es, modulo 1 zu rechnen. Der so erhaltene Wert wird mit der Anzahl
M der Tabellenplätze multipliziert und man erhält den Hash-Wert 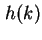 .
.
Die komplette Formel lautet:
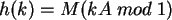
Beispiel:
Gegeben sei der Schlüssel k=11449 und die Anzahl der Tabellenplätze M=101. Mit Hilfe der oben
genannten Formel entsteht folgende Rechnung:
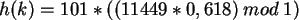
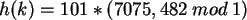

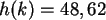
Der berechnete Wert wird abgerundet, wodurch man den endgültigen Hash-Wert 48 erhält.
Es gibt noch einige weitere Verfahren, um zu berechnen, welche aber nicht sonderlich interessant
erscheinen und jeweils nur eine Modifikation der beiden genannten Verfahren darstellen, deshalb wird auf eine
Beschreibung verzichtet.
Nächste Seite
Aufwärts
Vorherige Seite
Inhalt
Nächste Seite: Beseitigung von Kollisionen
Aufwärts: Hashing
Vorherige Seite: Hashing
Inhalt
2002-05-09