 :
:
Nach der erfolgreichen Berechnung des Hash-Wertes k bleibt immer noch das Problem der Kollisionen zu
lösen. Eine Kollision entsteht, wenn die Hash-Werte von zwei (oder mehr) Schlüsseln identisch sind.
Auch in in diesem Falle gibt es verschiedene Möglichkeiten, mit dieser immer wieder auftretenden
Situation umzugehen.
Getrennte Verkettung
Die einfachste Methode, um dieses Problem zu lösen besteht darin, Elemente, die den gleichen Hash-Wert
erhalten haben, miteinander zu verketten, also für jeden Tabellenplatz eine Liste zu bilden.
Dieses Verfahren wird Getrennte Verkettung oder auch seperate chaining genannt. Für den Fall,
daß häufige Kollisionen auftreten und die Listen dadurch sehr lange werden, empfiehlt es sich, diese zu sortieren
um die Suche nach darin enthaltenen Elementen zu verkürzen. Dazu können die im Kapitel Suchalgorithmen
aufgezeigten Verfahren verwendet werden. Generell ist es jedoch üblich, die entstandenen Listen mittels
sequenzieller Suche zu durchlaufen. Folglich muß darauf geachtet werden, daß die Länge der Listen nicht zu
groß wird. Das läßt sich dadurch erreichen, daß die Anzahl M der Tabellenplätze auf etwa ein Zehntel
der zu erwartenden Schlüssel festgelegt wird. Dadurch erhalten bei gleicher Verteilung alle Listen ungefähr zehn
Einträge, wodurch sich die sequenzielle Suche nicht laufzeitkritisch auswirkt.
Vereinfachtes Beispiel für :

Daraus ergibt sich folgende Tabelle:

Das stark vereinfachte Beispiel verdeutlicht die angewandte Methode. Elemente, welche den gleichen Hashwert
haben, werden einfach zu einer Liste verkettet. Die Zahlen der ersten Reihe spiegeln den Hash-Wert
der jeweiligen
Liste wieder. Der Kreis am Anfang jeder Liste stellt den Kopf der entsprechenden Liste dar, der schwarze
Punkt das Ende der Liste, was sich dem Gedankengang nach auf die Implementierung bezieht.
Codebeispiel
Folgendes Codebeispiel (Sedgewick) zeigt, wie sich eine Menge von M Listen mit M Listenköpfen
initialisieren ließe:
![\begin{listing}{1}
Dict::Dict(int sz)
{
M = sz; // Anzahl der Listen
\par z =...
...f
heads[i] ->next = z; // verweist auf das
// null-Element
}
}\end{listing}](img79.png)
Nun haben wir eine Methode kennengelernt, um Kollisionen zu vermeiden. Soweit so gut, doch jede Medaille hat
zwei Seiten, so auch diese. Nehmen wir an, die anfängliche Aufwandschätzung bezüglich
der zu erwartenden Schlüssel war nicht sehr gut, oder
es treten trotz eines vermeintlich guten Hash-Verfahrens sehr viele Kollisionen auf. Folglich würden einige
der Listen in unserer Tabelle zu einer Größe anwachsen, welche die Performance einer sequentiellen Suche
stark einschränken und sich nur durch eine aufwändige Erweiterung der Tabelle und Umverteilung der Elemente
lösen ließe.
Ein Beispiel für eine problematische Anwendung ist etwa die Implementierung eines
Telefonbuches, dessen Datensätze mittels Hashing in verketteten Listen gespeichert werden. Welches Problem ergibt sich dabei?
Nun, wenn wir uns die Verteilung der Namen betrachten stellen wir fest, daß es (bei einer größeren Stadt
tausende von Nachnamen gibt, welche mit dem Buchstaben S beginnen, aber im Vergleich dazu nur sehr wenige,
die mit den Buchstaben Q, X, oder Y beginnen. Das hat zur Folge, daß es trotz eines guten Algorithmus
zu häufigen Kollisionen kommt, welche sich auf die Länge der Listen auswirken. Ein Gegenmittel wäre die
Vergrößerung des zur Verfügung stehenden Speicherplatzes durch Erhöhung der Anzahl der Tabellenplätze
M. Die folgende Erläuterung beschreibt
eine andere Methode, um Kollisionen zu vermeiden und den Platz in der Tabelle voll auszunutzen.
Lineare Sondierung
Wie anfangs beschrieben, läßt es sich selbst durch einen sehr guten Hash-Alrogithmus kaum vermeiden, daß es
zu Kollisionen kommt, selbst wenn die Anzahl der verfügbaren Tabellenplätze M viel größer ist
als die Anzahl der Schlüssel N. Ein weiteres Verfahren, um entstandene Kollisionen zu vermeiden,
heißt offene Adressierung. Es bedeutet, das bei einer Kollision zweier Schlüssel das kollidierende
Element einfach auf einen anderen freien Tabellenplatz gespeichert wird. Wäre M=N
so enthielte jeder Tabellenplatz am Ende genau einen Schlüssel. Aber Vorsicht: M muß eine Primzahl sein!
Die Variante der offenen
Adressierung, die nun beschrieben werden soll, heißt lineare Sondierung oder lineares Austesten. Zur Verdeutlichung der Arbeitsweise verwenden wir wieder unser vorheriges Beispiel, mit dem Unterschied, daß  statt ist. Es sind zwar nur 15 Schlüssel, aber da
statt ist. Es sind zwar nur 15 Schlüssel, aber da 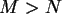 und gleichzeitig eine Primzahl sein muß, fiel die Wahl auf 17.
und gleichzeitig eine Primzahl sein muß, fiel die Wahl auf 17.
Beispiel:

Mit Hilfe der linearen Sondierung entsteht folgende Tabelle:

Wie ensteht diese Verteilung?
Im Grunde genommen ist das Vorgehen sehr einfach: Die oben berechneten Schlüssel werden gemäß ihrer
Hash-Werte in die Tabelle eingetragen. Kommt es zu einer Kollision, ist also ein Tabellenplatz schon
durch einen Schlüssel belegt, wird dieser einfach auf den nächsten freien Platz abgebildet.
Dies ist schon zu Beginn der Tabelle der Fall. Die Schlüssel v und e haben den gleichen
Hash-Wert. v wird ganz normal auf die Stelle 5 abgebildet. Soll nun der Schlüssel e
abgebildet werden, stellen wir fest, daß dieser Platz in der Tabelle schon belegt ist, also suchen wir
nach dem nächsten freien Platz. Dieser ist gleich nebenan, also an Stelle 6. Dort wird nun der Schlüssel
e abgelegt. Die nächste Kollision, auf die wir treffen, findet sich bei dem nächsten e.
Beim ersten Auftreten war der Platz 5 der Tabelle schon belegt, der nächste freie Platz an Stelle 6. Dieser
ist nun aber wiederum schon belegt, deswegen wird dieser Schlüssel auf Tabellenplatz 7 abgebildet.
Wir gehen die Plätze solange der Reihe nach durch, bis ein freier gefunden wird. Ist die Tabelle zu Ende, beginnt
die Suche nach einem freien Platz wieder am Tabellenanfang. Das Ziel, nämlich die gleichmäßige Verteilung der Schlüssel,
wurde erreicht.
Doppeltes Hashing
Der Nachteil beim linearen Austesten ist die oft lange Suchzeit, wenn sich die Tabelle zu füllen beginnt.
Gibt es viele Kollisionen, müssen bei der Suche auch dementsprechend alle Nachfolgepositionen untersucht
werden, um den richtigen Schlüssel zu finden, wobei auch solche untersucht werden müssen, die einen völlig
anderen Hash-Wert haben. Es gibt jedoch einen Weg, dies zu vermeiden: Doppeltes Hashing.
Grundsätzlich arbeitet Doppeltes Hashing nach dem abolut gleichen Prinzip, wie die Lineare
Sondierung. Der Unterschied besteht darin, daß eine zweite Hash-Funktion dazu benutzt wird, um eine feste
Reihenfolge festzulegen, nach welcher die nachfolgenden Tabellenplätze auf den gesuchten Schlüssel
getestet werden. Mit anderen Worten: Es werden bei einer Kollision nicht die genau darauf folgenden Plätze
duchsucht, sondern es wird eine Testfolge mit bestimmten Abständen festgelegt. (Was natürlich auch für
die Abbgildung der Werte auf die Tabelle gilt.) Wir erinnern uns: Die erste Hash-Funktion lautete  Die zweite Hashfunktion soll in diesem Fall
Die zweite Hashfunktion soll in diesem Fall
 lauten (Sedgewick).
Die Berechnung
lauten (Sedgewick).
Die Berechnung  bewirkt, das nur letzten drei Bits von k verwendet werden. Mancher mag sich
nun fragen, warum. Nehmen wir z.B. den Buchstaben R, welcher die 18. Stelle im Alphabet belegt. Binär
ausgedrückt (auf fünf Bitstellen) ergibt das 10010. Die letzten drei Bits davon in einen dezimalen Wert
umgewandelt ergeben den Wert 2. Abgezogen von 8 erhält man 6, was dem Ergebnis entspricht, das auch der
Taschenrechner produzieren würde, wenn man
bewirkt, das nur letzten drei Bits von k verwendet werden. Mancher mag sich
nun fragen, warum. Nehmen wir z.B. den Buchstaben R, welcher die 18. Stelle im Alphabet belegt. Binär
ausgedrückt (auf fünf Bitstellen) ergibt das 10010. Die letzten drei Bits davon in einen dezimalen Wert
umgewandelt ergeben den Wert 2. Abgezogen von 8 erhält man 6, was dem Ergebnis entspricht, das auch der
Taschenrechner produzieren würde, wenn man  eintippte.
eintippte.
Beispiel
Gegeben sei und 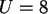 . Außerdem die Schlüssel, welche wir schon vorher verwendet haben.
. Außerdem die Schlüssel, welche wir schon vorher verwendet haben.

Dies führt zu folgender Tabelle:

Auch diese Tabelle ist ziemlich leicht nachzuvollziehen, wenn man sich die berechneten Hash-Werte ansieht.
Der erste Hash-Wert jedes Schlüssels dient dazu, den eigentlichen Tabellenplatz zu ermitteln, während
der zweite Wert zur Kollisionsbehandlung verwendet wird. Die erste Kollision tritt beim Schlüssel
e auf, da dieser den gleichen Hash-Wert hat, wie zuvor v. Bei der linearen Sondierung
würde e nun einfach auf den nächsten freien Platz abgebildet. In diesem Falle wird der zweite
Hash-Wert dazu verwendet, eine bestimmte Anzahl von Schritten zu gehen, um den damit ermittelten
Tabellenplatz
zu verwenden. Bei unserem Beispiel beträgt der zweite Wert 3, d.h. e wird genau 3 Plätze weiter
hinten auf die Tabelle abgebildet, also an Stelle 8. Wäre auch dieser Platz schon von einem anderen
Schlüssel belegt, würde erneut ein Tabellenplatz untersucht, der genau 3 Schritte dahinter liegt.
Trifft man dabei auf das Ende der Tabelle, beginnt man mit der Suche wieder von vorne. Der gleiche Vorgang
wird nun für alle anderen Schlüssel vollzogen, wobei der erste Hash-Wert immer den Tabellenplatz angibt
und der zweite Hash-Wert den Schrittabstand, den man gehen muß, falls dieser schon belegt ist.
Nächste Seite: Berechnung der Gleichverteilung
Aufwärts: Hashing
Vorherige Seite: Berechnung und Arbeitsweise
Inhalt